Building Event-centric Knowledge Graphs From News
![]()
Article Menu
/ajax/scifeed/subscribe
Open Access Review
A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions
Department of Computer Science, Universidad Técnica Particular de Loja, Loja 110105, Ecuador
*
Author to whom correspondence should be addressed.
Academic Editor: Ralf Krestel
Received: 30 March 2021 / Revised: 17 May 2021 / Accepted: 24 May 2021 / Published: 28 May 2021
Abstract
In recent years, the use of recommender systems has become popular on the web. To improve recommendation performance, usage, and scalability, the research has evolved by producing several generations of recommender systems. There is much literature about it, although most proposals focus on traditional methods' theories and applications. Recently, knowledge graph-based recommendations have attracted attention in academia and the industry because they can alleviate information sparsity and performance problems. We found only two studies that analyze the recommendation system's role over graphs, but they focus on specific recommendation methods. This survey attempts to cover a broader analysis from a set of selected papers. In summary, the contributions of this paper are as follows: (1) we explore traditional and more recent developments of filtering methods for a recommender system, (2) we identify and analyze proposals related to knowledge graph-based recommender systems, (3) we present the most relevant contributions using an application domain, and (4) we outline future directions of research in the domain of recommender systems. As the main survey result, we found that the use of knowledge graphs for recommendations is an efficient way to leverage and connect a user's and an item's knowledge, thus providing more precise results for users.
1. Introduction
In recent years, the use of recommender systems (RS) has become popular on the web. From the user's perspective, this type of system helps alleviate information overload because users receive personalized content or resources according to their profile or preferences. On the other hand, product or web content providers are betting on this type of service because they can capture the interest of their customers or users and, as a result, improve their sales or increase the use of the content they offer. For researchers, behind a recommender system [1], there is knowledge, processes, techniques, and challenges to address in order to improve the results and users' experience. In recent years, the emergence of knowledge graphs (KGs) has directed research on recommender systems towards the processing of this type of content. For a better understanding of the work that has been published so far on the subject, in this study, we identify and analyze the literature in which KG-based recommendation systems have been addressed.
Since their inception, recommender systems have been categorized as content-based (CB), collaborative filtering-based (CF), and hybrid (commonly content + collaborative + demographic) [2]. Currently, research related to recommender systems has increased considerably, creating new recommendation methods and combining different algorithms, ranging from more traditional [3] to hybrid [4] and knowledge graph-based methods [5].
Information filtering systems can be a key to discovering knowledge in an information-rich environment such as the web. However, traditional approaches do not have sufficient capacity to reflect and exploit this knowledge [6]. A recommender system can leverage knowledge to build a semantic representation and to identify the most important entities and items for system users.
Today, KGs have become important resources to support tasks such as web searches, recommender systems, and question-answering systems. A knowledge graph is a structure that describes entities or concepts and connects them using different types of semantic relationships [6]. Graph-based recommendation methods are attracting attention in both academia and industry. In this study, we analyze 38 papers addressing the topics of recommendation and KG.
In domains such as education, RSs have become an important field of research [7]. Specifically, KG-based RS focus on supporting learners by finding educational resources [8] or relevant academic content that they can be integrated into their learning process [5,9,10]. Likewise, in other areas such as tourism, RS can deliver personalized information to users, thus enhancing their tourism experience [11,12,13,14,15,16]. Other domains upon which research on knowledge graphs has been focusing are health [17,18], entertainment [19], and business [14,20].
In addition, during the research, we came across studies that discuss knowledge graph applications in different domains [6,21,22,23,24], and their advantages and disadvantages, but only some are oriented on the analysis of the technologies used, their development, and their method of evaluation.
Regarding the state of research on KG-based RS, we found two studies where the topic is addressed: Liu et al. in [6] presented a survey focused on Knowledge Graph Embedding (KGE)-based recommendation methods, and Wang et al. [25] presented a tutorial focused on the recommendation problem from the perspective of graph learning and reasoning. When we broadened the search, we found multiple literature reviews or studies in the area of recommender systems, although most of them focused on theories and applications of traditional recommendation approaches.
Therefore, although there is a variety of literature on this subject, only two studies analyzed the role of KG-based RS [6,25]. The limitation is that they focus on a segment or subgroup of recommendation methods. In this paper, to overcome this information gap, we present the following contributions:
-
We explore traditional and more recent developments of filtering methods for a recommender system.
-
We identify and analyze proposals related to knowledge graph-based recommender systems.
-
We present the most relevant contributions by application domain.
-
We outline future directions of research in the domain of recommender systems.
The rest of the paper is organized as follows: Section 2 presents filtering approaches for recommender systems. Section 3 describes recommender systems based on knowledge graphs. Section 4 describes the methodology carried out in this survey. Section 5 shows the results of the literature review. Section 6 provides an overview of the future research directions. Finally, Section 7 presents the conclusions and future work.
2. Filtering Approaches for Recommendation Systems
Over the years of developing theory on recommender systems, three main generations of recommender systems have been developed. The first-generation RS (1995–2005) is based on three main approaches: content filtering, collaborative filtering, and hybrid methods; their methods are statistical or based on machine learning techniques. Second-generation RS (2003–2014) is based on context such as time, location, features such as ratings of user's group, etc. Research on this generation of RS is still ongoing, but third-generation RS is growing to be increasingly interesting. These RSs focus on semantic models of representation and the use of all knowledge components involved in the process of making recommendations [26].
2.1. Collaborative Filtering
The collaborative filtering approach (CF) is a traditional recommendation method that makes recommendations based on common user preferences and historical interactions [21]. This approach can be divided into memory-based methods and model-based methods. Memory-based methods, in turn, can be of two types: user-based and item-based. The most popular algorithm of memory-based approach is the KNN algorithm; this algorithm uses some traditional similarity measures such as Pearson correlation, Spearman, Coseno, Jaccard, etc. [2]. On the other hand, within the model-based methods, the most used are the factorization matrix (MF [27]) and its variants (NMF [28], SVD [29]).
Currently, new model-based collaborative filtering methods have been developed, for example Bayesian [30,31,32], clustering-based [33,34], rule-based [35], and graph-based [36] methods.
Collaborative filtering suffers mainly from two problems: sparsity of users' data when there are few interactions between the user and the items, and cold-start problem (new user and new item). An important aspect to consider is that traditional recommendation technology does not leverage semantic information, keyword relationships, and hierarchical structure [37].
2.2. Content-Based Filtering
A content-based recommender system learns to recommend items that are similar in terms of content features to those that the user liked in the past [38], i.e., this approach uses items' information to recommend based on user profiles.
Content-based recommenders can be classified into case-based reasoning [39] and attribute-based technique [40]. The case-based reasoning technique recommends items highly correlated with items that the user liked in the past. In contrast, the attribute-based technique recommends items based on matching their attributes with the user's profile.
Content-based filtering (CBF) suffers from some limitations such as overspecialization, limited content analysis, serendipity, and new user problems [41].
Most content-based recommender systems use simple models such as keyword matching or Vector Space Model (VSM) with Term Frequency-Inverse Document Frequency (TF-IDF) weighting [38], topical modeling to extract the semantic structures hidden in the document-based dataset by assigning topical distributions to the documents [42].
2.3. Demographic Filtering
Recommendation systems based on demographic filtering are based on the fact that users with certain common personal attributes (gender, age, country, etc.) also have common preferences [43]. Based on this, these systems can generate recommendations by categorizing users according to demographic attributes. These approaches are especially useful when the amount of item information is limited.
An advantage of demographic filtering is that it does not require user ratings of items that are necessary for content-based and collaborative filtering approaches.
However, this type of filtering has some disadvantages [44]: (1) Collecting complete information for users is not practical due to the security and privacy issues involved. (2) Demographic filtering is mainly based on user preferences, which forces the system to recommend the same item to users of related demographic groups.
2.4. Context Aware-Based Filtering
Context Aware-based Recommender System (CARS) is the most popular approach for incorporating context information. This approach assumes that the context is defined with a predefined set of observable attributes, for which the structure does not change significantly over time [41]. Context information such as time, location, geometric information, or the accompaniment of other people (e.g., friends, girlfriend/boyfriend, relatives, or colleagues) has recently been considered in recommender systems [39,45,46].
Contextual information provides additional information for making recommendations, especially for applications where it is not sufficient to consider only users and items [47].
2.5. Knowledge-Based Filtering
A knowledge-based recommender system suggests items to the user based on domain knowledge about how the items satisfy the user's preferences [48]. According to [38], these systems should employ three types of knowledge: knowledge about the users, knowledge about the items, and knowledge about the correspondence between the item and the user's needs.
Knowledge graphs can provide complementary information to overcome the problems faced by collaborative and content-based filtering approaches [21], since their recommendations are not linked to ratings; instead, they use domain knowledge. However, the main drawback of knowledge-based recommenders is that their creation involves having skills in knowledge engineering [49].
On the other hand, the semantic relationships present in a KG can be used by the system to improve its accuracy and to increase the recommended items' diversity. Based on this feature, novel KG-based approaches have been developed on the basis of classical approaches. For example, Reference [50] presented an approach for collaborative filtering with implicit comments where interactions between users and items are learned using a knowledge graph embedding method. Another proposal was explained in [51]; in this case, the recommender system for E-commerce uses a knowledge base to identify the domain knowledge of users, items, and the relationships between them.
In keeping with the idea that knowledge-based approaches do not experience the problems of traditional methods, this survey focuses on analyzing studies and applications developed with knowledge-based technologies for the recommendation process.
2.6. Hybrid Filtering
These systems commonly combine collaborative filtering with content-based filtering or collaborative filtering with any other recommendation approach. The goal of combination is to leverage each approach's advantages and to improve the overall system performance [38].
Currently, some works on hybrid approaches are based on deep learning methods [52,53], Bayesian networks [54,55], clustering [56,57], latent features [58,59], and graphs [60,61].
3. Recommender Systems over Knowledge Graphs
In 2012, Google proposed the term knowledge graph to refer to the use of semantic knowledge in web searches. Although the term associated with KG is new, representing pieces of knowledge as interconnected nodes is not a new idea. We can consider current KGs as an evolution of semantic networks, an old concept that emerged from the literature on cognitive science and artificial intelligence.
When Google created its KG, the purpose was to improve the search engine's capability and to enhance users' search experience [21]. Today, several companies and researchers have joined this movement and have created different KGs to describe specific domains. Before the term "knowledge graph" became popular, DBPedia and other linked data (LO) sets were generated thanks to Semantic Web technologies and the Linked Data—Design Issues proposed by Berners-Lee.
A knowledge graph provides machine-readable data organized as a graph; graph-data describes and interconnects entities of an open or a close domain. The data in a KG is accessible through the web and can be consumed automatically; these characteristics have facilitated the creation of applications such as [21] question-answering, recommender systems, information retrieval, domain-specific applications by knowledge area, and other applications (social networks and geoscience).
Concretely, KG recommendation exploits the connections between entities representing the users, the items to be recommendeded, and their interactions. The connections, explicit or not, are used by the system to identify items that may be interesting or useful to the target user [62]. Thus, relationships provide the KG-based recommender with additional valuable information to apply inference between nodes to discover new connections [63]. On the contrary, in general, classical recommendation methods based on feature vectors overlook such connections, which may result in suboptimal performance, especially when there is data sparsity [25].
The availability of knowledge graphs in different domains has motivated researchers to conduct studies on knowledge graph-based recommendation algorithms. According to [6], current KG-based recommendation approaches can be classified into three categories: ontologies-based recommendation, linked open data-based recommendation, and knowledge graph embeddings-based recommendation. Furthermore, according to [21], KG-based recommendation can be classified into path-based approaches.
3.1. Ontology-Based (OB) Recommendation
In this approach, ontologies are used to model knowledge about users and their context, knowledge about the items, and knowledge about the domain.
In addition, the structure and semantics defined by an ontology facilitate the creation of rules to generate recommendations based on explicitly specified constraint or rules. That is, elements that satisfy the rules with respect to a given set of user's requirements are generated as a recommendation [64].
As explained by [38], similar to knowledge-based recommender systems, ontology-based recommenders do not experience most of the problems associated with conventional recommender systems, i.e., cold-start, sparsity of rating data, and overspecialization problems. The above is possible to achieve due to the fact that recommendations are based on user, item, and domain knowledge rather than based on user ratings.
Although OB recommendation exhibits advantages as indicated above, there are also some disadvantages related to the creation of an ontology, since this process is time-consuming and depends on an expert. To overcome this challenge, there are some proposals that demonstrate that the ontology creation process is possible to automate [38].
3.2. Linked Open Data (LOD)-Based Recommendation
Rich semantic information queryable from LOD data sets can enrich the system information, thus finding similar attributes among items to be recommended. The underlying advantage of doing this is to overcome the problem of data sparsity. On the other hand, as the recommendation process depends on external data, then the integrity of the external data may affect the recommendation results [6].
3.3. Embedding-Based Recommendation
In recent years, Knowledge Graph Embedding (KGE) techniques are becoming increasingly popular because they offer a simple and efficient way to generate recommendations [6]. In this case, the KG is transformed by using KGE algorithms; then, a recommendation framework can leverage the learned entity and relationship embeddings to produce a set of results [21].
An embedded KG can represent entities and relationships in a continuous vector space while preserving certain network information. The goal of applying KGE methods is to simplify the processing of a KG while maintaining its structure. In recommendation, KGE can be used to enrich the information of users and items, then the embedding representations can be used to calculate the similarity between both [6]. Among the most popular KGE models are TransE, TransH, TransD, and TransR [65].
In general, the introduction of KGE in recommender systems consists of using traditional recommender algorithms. Liu et al. [6] stated that, according to the relationship between knowledge graph embedding and the recommendation algorithm, there are two main ways to realize these tasks: independently learning and jointly learning. In this study, the authors analyzed different recommendation proposals based on this type of approach.
3.4. Path-Based Recommendation
The path-based recommendation is a natural and intuitive way to use KGs in recommendation processes. The algorithms attempt to explore various patterns of connections between nodes in a KG to retrieve additional information for recommendations. This method relies on hand-crafted designed meta-paths, which are difficult to optimize in practice, and it is not possible to design in some particular scenarios where entities and their relationships are not within a specific domain [21].
4. Methodology
In this section, we describe the tasks performed to find the literature related to the application of recommendation methods based on knowledge graphs. Figure 1 shows the general flow of the executed process that consists of three stages: search, selection, and analysis. The results of the last stage are discussed in Section 5.
4.1. Search
To find literature related to the topics of interest, we conducted a systematic method of searching based on keywords and used Scopus as a source of information. To determine the most relevant studies in the area, we used Scopus's advanced search interface to filter the results.
To identify the documents indexed by Scopus, we designed a search that combined: (1) keywords related to the subjects (KG and RS), (2) keywords related to types of studies (survey, mapping, review, etc.), and (3) publication period between the years 2014 and 2020.
Listing 1 defines the final search string that was run in Scopus and allowed us to retrieve 79 documents.
| Listing 1. Search query. |
| ABS ( content AND filtering )) AND (ABS (" knowledge graph ")) |
| AND |
| (TITLE -ABS ( review ) OR TITLE -ABS( survey ) OR TITLE - ABS( state ?of?the ?art) |
| OR TITLE -ABS( SOTA ) OR TITLE -ABS( mapping ) OR TITLE ( study )) |
| AND |
| PUBYEAR > 2013 AND PUBYEAR < 2021 |
4.2. Selection
To identify relevant papers within the study area, we chose two characteristics of the articles as inclusion criteria: (a) document type = [Article|Proceeding Paper | Review], and (b) language = English. Applying these two filters, we discarded 33 papers: 30 because they were conference reviews and 3 because they were written in Chinese.
Based on the title and abstract of the 46 papers selected in the previous step, we performed a preliminary screening of papers to verify their inclusion or non-inclusion in the group of papers to be analyzed. In this second step, we established three reasons for exclusion from this study:
-
Relation with the topic of interest. If the document did not describe a study or did not refer to the application of recommender systems in knowledge graphs, then it was excluded.
-
Availability. If the document was not available online or if access to its complete content was not possible, then it was excluded.
-
Duplicity. If there was more than one paper on the same topic and corresponding to the same authors, the most recently published paper was chosen.
After applying the criteria above, the corpus of documents to be analyzed was finally reduced to 38 papers. Of this group of reference papers, 5% were reviews, 37% were journal articles, and 58% were conference papers.
Figure 2 presents the annual distribution of articles found in Scopus. Additionally, the figure presents two series, the one corresponding to the selected papers vs. the series of papers that were excluded because they did not meet the abovementioned criteria.
As can be seen in Figure 2, in the last two years of the study, interest in the use of KG in recommender systems increased. Although scientific production grew in the area, a further increase is expected in the coming years considering the nature, heterogeneity, and large volume of data in the cloud.
To identify the most relevant terms in related works, we constructed term networks using the VOSviewer tool. Figure 3 presents the term network built based on the author and index keywords, and Figure 4 presents the most frequent words found in the titles and abstracts of the papers.
As can be seen in Figure 3 and Figure 4, some terms are present in both networks, such as knowledge graphs and recommender system. While other simple words such as data, user, item, or model only appear in the second network. In any case, the two figures highlight the terms discussed in this research.
4.3. Analysis
After we found the related papers to the topics of interest, we defined the categories and criteria used to organize and characterize them.
First, we identified the technologies and methods mentioned or used in each paper. Here, we considered two approaches: (a) technologies related to KG and semantic web, and (b) information recommendation or filtering methods. The results of this category of analysis are presented in Section 5.1.
Second, to determine the completeness or stage of maturity of each proposal, we classified each paper according to the following:
-
Level of development. If the work presented a proposed high-level KG recommendation or if it referred to recommendations as a potential application of KGs, then the work was classified as conceptual. If the analyzed work presented a new recommendation method or if it presented the application of existing methods, then the work was classified as implementation.
-
Type of evaluation. Regarding the type of evaluation carried out in each analyzed work, we considered three values: (1) experiments and comparative evaluation, if the authors performed experiments and compared their proposal with other baseline models, using performance metrics; (2) experimental results, if the proposal was evaluated using qualitative approaches or using exploratory experiments of the results; and (3) no evaluation, if no type of evaluation was found.
The analysis results are discussed in Section 5.2.
Finally, we attempt to organize the contribution of the selected papers according to the application domains. Here, we identify for each domain, the datasets used or mentioned in each paper, and the main findings reported in the literature. The results are available at Section 5.3.
5. Results
This section presents the results of the analysis carried out on 38 papers related to the topics of knowledge graphs and recommendation systems. In Section 4, we explained how we searched for and selected the analyzed literature.
The analysis results were organized into three categories of information. First, we identified the technologies or methods referred to, used, or proposed in each research. Second, we identify the level of development and type of evaluation carried out in the set of papers analyzed. Finally, we present the main contributions found by the application domain.
5.1. Technologies and Proposals
In this first category of analysis, we classified the technologies into two subcategories: KG and Semantic Web Technologies, and Recommendation and Artificial Intelligence Methods.
5.1.1. Knowledge Graphs and Semantic Web Technologies
Knowledge Graph and Semantic Web offer an approach and a set of technologies for structuring, organizing, publishing, accessing, and processing linked data. Additionally, the organized data in a graph facilitates the construction of intelligent applications [5] such as recommender systems. Table 1 identifies the main technologies of this type that were found in the analyzed papers.
As illustrated in Table 1, six groups of technologies or approaches are the most popular.
The most popular group corresponds to technologies related to KGs and linked data (LD). In some works such as [74,76,77], the authors bet on the reuse of linked datasets such as WordNet, DBPedia, Wikidata, Freebase, or Google Knowledge Graph. In other cases, the authors propose the creation of new KGs such as the Question-Answering KG [18], Event-centric Tourism Knowledge Graph (ETKG) [15], POI-Sensitive Knowledge Graph [20], Cohort Knowledge Graph [75], among others. Other works perform both tasks, i.e., create a KG (DBP-FB) and reuse other existing sets to enrich or complete information on the original graph [80]. Finally, another group of works corresponds to studies that discuss certain tasks related to KG [13,22,63,73,82].
Regarding the second group of technologies, more than 55% of the papers refer to KGE. Regarding the KG representation method (KGE), the use of a predominant method was not found. Different works highlight the use of different methods: TransE [10], TransD [68], RotatE [50], and TransH [20].
The third most popular group of technologies are ontologies. To support recommendation processes, among the ontologies created are Semantic Sensor Network Ontology [17], Application Feedback Ontology [70], and Study Cohort Ontology (SCO) [66,75]. Some papers reuse ontological models available on the web, such as Semantic Science Integrated Ontology (SIO) [66], DBPedia ontology [77], and SKOS [79].
Other technologies that stand out in the other groups are SPARQL to query data from the KG [15,79], RDF to populate the KG with data [15,66,67], the Neo4J base to store graph data [70,81], among others.
5.1.2. Recommendation and Artificial Intelligence Methods
Table 2 shows the recommender approaches commonly used with KG technologies. One of the most commonly used approaches in combination with knowledge graphs is collaborative filtering. Methods such as neural networks, factorization matrix, deep learning methods, and Linear Support Vector are used to find user preferences. On the other hand, it can also be observed that KG-based methods use content-based filtering to generate recommendations based on the content of the items to be recommended. Most of the papers that incorporate this approach use similarity measures (e.g., Cosine) or Word2Vec to determine the similarity between different types of content or to cluster vectors of similar words.
Table 2 illustrates that some works use a knowledge-based approach as an alternative method to collaborative filtering in order to solve cold-start problems. These systems use reasoning techniques to exploit the information of the KG and inference methods to make recommendations.
The literature review results also show that another approach that can be used with KG is context-aware; however, few papers use this approach.
As shown in Table 2, most of the analyzed works on KG employ a hybrid approach combining more than one recommendation method. Apart from these methods, there are other recommendation approaches that can also be combined with knowledge graphs, e.g., user group recommendation approaches [9,83], conversational approaches [84,85], and social network-based [86,87].
5.2. Development and Evaluation Levels
In this section, we summarize the level of development and type of evaluation carried out in the set of papers analyzed. Figure 5a indicates that approximately 6 out of 10 of the papers analyzed reached an implementation phase, either in the construction of the KG and/or the recommender system. Another set of these articles correspond to conceptual studies that do not contemplate the construction of the solution. Figure 5b demonstrates that a low percentage of the papers focus on experiments that do not contemplate comparison with other methods or algorithms. These proposals are mainly focused on evaluating user's satisfaction and opinion, usability and usefulness of the recommendations, effectiveness, efficiency, and robustness of the KG-based approaches. On the other hand, 18 papers did not include an evaluation process because they focused on surveys of techniques based on KG, recommender system architectures incorporating KG, identification of problems faced by knowledge graph methods, etc.
From Figure 5b, we can also conclude that a total of 24 papers include an experimental phase and a comparative evaluation with other methods. The results of these works are tested using some quality measures such as the following:
-
Precision, recall, and F-measure are used when a recommender system must make decisions such as making or not making a recommendation. These measures are commonly used to evaluate the performance of recommender systems [88].
-
Normalized Discounted Cumulative Gain (NDCG) allows for measuring the quality of the rank. NDCG is widely used to measure the effectiveness of recommendation algorithms [88].
-
Mean Reciprocal Rank (MRR) measures whether the recommender system places the user's relevant items at the top of the list [3].
-
Novelty and Diversity. Novelty measures the ability of RS to recommend items that appear novel to the user [89]. Conversely, diversity measures the ability of the RS to recommend items that are not similar to those preferred by the user in the past or that is not limited to recommending popular items only [90,91].
From the review conducted, we found that most of the papers that evaluate performance focus on measuring precision or NDCG while the other metrics are considered in less than 4% of the papers analyzed. This result indicates that current research is focused more on the evaluation of recommendation quality, entity-relationship ranking, and their relevance instead of evaluating, for example, the diversity and novelty of recommendations. Other measures that are little used are runtime, Mean Average Precision (MAP), and AUC-ROC.
5.3. Contributions by Application Domain
In this last category of analysis, we classified each paper according to the application domain, the recommended item, and the data source(s) used as the basis for generating the recommendations. Table 3 summarizes the results of this task.
As we can see in the Table 3, the most popular application domain for the KG-based recommendation is entertainment. For this domain, there are eight proposals out of the 38 analyzed. Additionally, here, we can observe that sound, music, and movie resources are the most recommended items. Moreover, some papers used more than one datasource to construct the KG and/or to carry out the recommendation experiments; for example, Reference [78] used two datasets to recommend music and movies.
The second most popular domain is E-commerce, business, and finances; in this case, the type of item recommended is diverse. The third group of applications is not focused on a particular area, i.e., proposals are cross-domain.
Another commercial area of application of RS is tourism and lodging; in this domain, the most popular dataset is Yelp, which has been used to generate different item recommendations such as POIs, restaurant services, and travel routes.
Finally, education and health are domains where recommendation systems are used to a lesser extent.
Below, we summarize the main paper's contributions for each application domain.
5.3.1. Education
As a contribution to the education sector, some KGs were created. In [9], a graph describing concepts and terminology of the cybersecurity domain was shown. Additionally, this KG contains information to help instructors and students track individual learning progress.
Interaction data sparsity during recommendation is an issue tackled in some proposals. The lack of rating data is a common scenario that can occur in academia, especially in open and non-formal education. To address this problem, Reference [10] proposed a hybrid model that recommends papers based on the browsing history of students of an academic search engine. Since the users of interest have no previous interactions in the recommender system, the proposed model can learn mappings between users' browsed papers and users' clicks on the recommended items.
Finally, in [5], an improvement in the accuracy of semantic similarity calculation between topics or concepts in a subject area is demonstrated. As the authors argue, the computation of semantic similarity plays a fundamental role in implementing a recommendation service for large educational datasets. According to the authors, current semantic similarity methods focus either on the structure of the semantic graph or only on the conceptual information. Therefore, in [5], a semantic similarity method is proposed, which combines these two methods and uses conceptual information to weigh the shortest path length between concepts. In the experiment, the authors demonstrate that their method has a certain degree of feasibility and credibility in calculating the semantic similarity of topics in KGs.
5.3.2. Health
In the health sector, we found four proposals related to knowledge graphs. In [66,75], the Study Cohort Ontology (SCO) is presented, which facilitates clinicians to perform population analysis and to generate cohort similarity visualizations. In this way, clinicians can select the most appropriate study populations for trial applicability.
Another study is [17], which deals with human care services [17]. In this case, data from different IoT sensors are used to recognize the current situation of a user and to predict future events. According to the authors, the current state of research about smart healthcare services focuses on analyzing user's behavior from single sensor data. Additionally, it focuses on analyzing and diagnosing the current situation of users. Therefore, a method is required to effectively manage and integrate a large amount of IoT sensor data. In the cloud, IoT sensor data stored in individual CKAN can be integrated based on common concepts. As a result, it is possible to generate an integrated knowledge graph considering data interoperability, and the underlying data are used as a base for prescriptive analysis.
Finally, in the healthcare field, the system proposed in [18] stands out. The system provides online instructions for volunteers of a suicide rescue organization called Tree Hole Rescue. The evaluation shows that the system provides answers, with high accuracy, to questions from users of the rescue organization. Additionally, the authors provide a set of methods to improve the system's question and to answer catalogue update capability.
5.3.3. Lodging and Tourism
Building KGs for lodging and tourism generally describe users and items (such as hotels, events, tourist attractions, and points of interest) as well as user–user or user–item interactions. Specifically, the KG proposed by [13] captures the logical associations between customer records (historical data on their movements and social communications).
Furthermore, Reference [11] showed that, by applying appropriate methods, the graphs can learn personalized weights of each user and the item to recommend, depending on the factors that most influence the customer's decision process. Another feature is that the graph can incorporate and connect heterogeneous information from location-based social networks (LBSN) into a unified representation space.
Another graph that can be highlighted is the Event-centric Tourism Knowledge Graph (ETKG), presented in [15]; the graph models the temporal and spatial dynamics of tourist trips. A relevant feature of ETKG is that it allows for representing dynamic data as activities that tourists can perform during a trip. The graph interconnects events using temporal relations in chronological order. Moreover, some additional features such as spatial information and attributes of journeys are incorporated into ETKG.
Regarding the recommendation, the proposed systems attempt to leverage networks of entities built from several sources. Concretely, the recommendation system proposed by [11] integrates relevant factors and features that influence user check-in behavior. In this study, the authors demonstrate that KG technologies allow for embedding heterogeneous information in unified representation space.
Moreover, KG-based recommendation can leverage weighted users' or items' properties according to their influence on the users' preferences. The method proposed by [16] can distinguish relevant customer's information to recommend hotels using a recurrent neural network and an attention-like mechanism.
In the tourism domain, we found that some works focus on addressing the sparsity of information and cold-start issues. Zhang, Wang, and Luo in [50] proposed the KGE-based collaborative filtering method that uses a deep neural network (DNN) to predict links that represent user–item interactions. Likewise, Reference [16] addresses a similar data completion task to predict user–item interactions. In [14], the authors tried to alleviate the cold-start problem by using the fine-grained restaurant services' features to identify similar users when a new user is coming.
Concerning the performance of the analyzed works, in general, an improvement is observed compared to other recommendation methods taken as a baseline. The RNN-based recommendation model of [16] predicts the interaction between users and hotels better (according to MAP and ROC-AUC) than the other three recommendation models. Likewise, the proposal of [11] is better in accuracy, recall, and MAP against eight different models, considering three evaluation datasets. Another method that improves the recommendation performance is ETKGCN [15], which recommends POIs related to tourist attractions. According to the authors, its performance is better because it integrates information from user reviews, a feature little exploited in other tourism networks.
In conclusion, the improvements achieved during recommendation are not only due to the use of appropriate recommendation or filtering methods but also due to the use of knowledge graphs.
5.3.4. Entertainment
In the entertainment domain, we found some works related to enrichment and link data with external sources. Regarding the enrichment of original data, Reference [69] proposes to use data available in linked open data (LOD) datasets. Specifically, Reference [74] proposes to connect the data of sound and musical items with external graphs such as WordNet and DBPedia; thus, the initial data are enriched.
Regarding KG-based recommendation, from a practical point of view, we highlight here some particular features of some proposals focused on the recommendation of entertainment items:
-
Dynamic data. Fischer et al. [72] proposed a system that recommends entities by taking advantage of the temporal nature of search log data. This approach can significantly improve the quality of recommendations compared to certain static models of relevance; particularly, it improves the freshness measure.
-
Leveraging multiple variables and relationships. The recommendation proposal of [76] jointly exploits user ratings and item metadata. The recommendation engine of [74] combines different features such as semantic content and collaborative information obtained from implicit user feedback.
-
Explainable recommendation. According to [19], ranking items and entities in the KG can serve as an explanation for recommendations.
-
Reusing of existing technologies and models. The architecture of [72] is based on previous work. On the other hand, Reference [19] proposed pre-trained or built models that can be run without training, thereby allowing faster deployment in new domains.
-
Performance improvement. Zhang, Wang, and Luo [50] demonstrated that the model KGECF achieves stable performance on five different datasets. In this case, among the reasons why KGECF is more stable is because (1) it can learn user's preference patterns more accurately and (2) the method used to embed the graph (RotatE) has very stable performance in modelling different types of relationships, such as one-to-many, many-to-one, and many-to-many relationships.
5.3.5. E-Commerce, Business, and Financial Sector
In e-commerce, certain items do not receive user feedback or do not have reviews, or there are users without historical data. To solve the lack of data, Reference [70] proposed an ontology as the driver to build users' profiles using multiple dimensions such as user's feedback, reviews, and user's ratings. In this way, the ontological model facilitates understanding the user-specific preferences by modelled from numerous perspectives.
Other works evidencing the use of multiple entities and data dimensions such as (1) Reference [68] present DCDIR, which utilizes a cross-domain mechanism to give personalized recommendations for new users in the insurance domain; (2) the KG built-in [20] incorporates data from supply-demand networks between business services and users, community network structures between users and between services, POIs, and detailed service content; (3) in [20], the KGE method called TransH is used to create dense representations of a KG; TransH facilitated the prediction of underlying relationships between users, POIs, and business services accurately.
On the other hand, for recommending business services, the experimental results of [20] demonstrate that the POIKG RS algorithm performs better than other collaborative filtering methods (Popularity, UserCF, ItemCF, and SPrank), especially when the data is sparse, which corresponds with a practical online scenario. Additionally, the approach can utilize the characteristics of different user groups and their POIs, resulting in better recommendation accuracy. Finally, POIKG RS presented significant online performance, i.e., when a user posts a comment on a service, they receive recommendation services immediately.
Unlike some proposals that focus on analyzing data sets from large companies such as Amazon, the system proposed by [51] was designed to be used by small-scale enterprise and retail shops, i.e., for companies where the number of users is small. As the authors emphasize, each user is important; therefore, the system should learn more about them based on their navigation through the website. To process KG based on user, product, and activity data, a knowledge-based collaborative filtering technique is used in [51]. The efficiency of this approach (accuracy, recall, and NDCG) is better than that of the benchmark systems evaluated.
In the financial sector, in [79], the authors automatically personalize and contextualize user's actions to improve the effectiveness of customer contract risk management. The approach integrates business and external data into a knowledge graph and interprets profile-based actions through semantic reasoning over KG. One of the main contributions of the work is to help select actions that better mitigate risk related to financial actions. Unlike other proposals that use automatic metrics for evaluating the system performance, in [79], the authors use usability measures for business managers to assess their proposal.
5.3.6. Cross-Domain
In cross-domain, we place those proposals that do not explicitly define the scope of application. In this group, we find different types of research:
-
Surveys that mention the recommendation term as (1) an application of KG [21,22], (2) KGE methods [65], (3) learning and reasoning on graph for recommendation (Wang2020c), (4) representation learning for dynamic graphs [63], (5) entity alignment [80], (6) relation extraction [73], (7) embedding mapping approaches [71], (8) knowledge base construction from unstructured text [67], and (9) extraction of semantic trees using KG [77].
-
Survey on KG-based recommendation. In [6], KGE-based recommendation algorithms are presented. Additionally, the authors analyze the existing literature and compare five specific studies.
-
Recommendation as secondary task. In [81], the authors present KG construction and the use of open source code to make recommendations. The graph is used to provide recommendations for language units.
-
Recommendation as a central task. In [78], the model Knowledge-Aware Sequential Recommendation (KASR) is presented. KASR provides sequential recommendations, capturing both the sequence of interactive records and the semantic information in KG simultaneously. In this paper, the authors introduce the relation attention network to explicitly aggregate the high-order relevance in KG, and a unified knowledge-aware GRU directly plugs the significance into the modelling of interaction sequences. The authors have conducted experiments on three real-world datasets, and the results demonstrate that (1) knowledge-transfer based on relevant attributes helps to capture users' preferences more accurately and (2) the relation attention network mines the rich semantic information in KG.
6. Future Directions
There are some interesting directions to explore in future studies related to recommender systems based on knowledge graphs; however, in this section, we highlight four future directions that we find interesting to delve into.
6.1. Interpretability of Recommendations
Most recommendation models focus on achieving good performance from the point of view of accuracy. However, if the user cannot interpret the results, then the reliability of the system is reduced [3].
In KG-based recommender systems, the relationship between users and items can be easily interpreted from entities and relationships [16]. Furthermore, knowledge graphs contain rich semantic associations between entities, which can be used to strengthen the relationships between recommended items and to provide interpretability during recommendation [6].
In recent years, methods based on knowledge graphs have been proposed to interpret recommendations such as KPUP [92] and entity2rec [93], which in addition to presenting a higher accuracy, make recommendations easily interpretable. Although some works have been developed using knowledge graphs, it is necessary to focus on how to use KG technologies to solve interpretability problems and to design interpretable models that lead to the explainability of the recommendation results.
6.2. Explainable Recommendation
Most of the research on explainable recommendations is based on unstructured data, such as text, images, audio, video stills, etc. However, if the recommender system possesses some knowledge about the recommendation domain, it facilitates the generation of personalized recommendations and explanations.
Currently, the advancement of KGE has made it possible to integrate graph embedding learning and recommendation techniques for improving the explanation of recommendations. Thus, the system can make recommendations with some domain knowledge and can tell the user why such items are recommended. For example, in [16], they develop a recommendation method to predict interactions between users and items using a KG and review text; in this case, explanations are generated based on the prediction made from the paths between a user and an item. Likewise, in [94], they use knowledge graphs to explain recommendations to users with items' unstructured textual description data.
Research on KG-based models for explainable recommendation represents one of the future directions for intelligent systems research since they can provide personalized recommendations in many research areas, such as personalized medical care, personalized online education, conversational systems, etc. Moreover, some studies on explainable recommendations [19,95] have demonstrated that explaining recommendations increase trust, transparency, and user acceptance in KG-based recommender system responses.
6.3. KG-Based Dynamic Recommendations
One of the few concerns of current KG-based recommendation algorithms is to make recommendations dynamic. Most KG-based recommender systems are considered static; although they present good accuracy results, very few consider users' dynamic preferences.
Dynamic recommendations are very important in areas such as healthcare where it is necessary to perform an evaluation of a patient's treatment over time [96], and in e-shopping [97] and social networks [98], where a user's interest can be influenced by other users very quickly.
Research that has focused on making recommendations dynamic is largely those based on traditional approaches such as collaborative filtering and/or content-based. Thus, a future direction is to leverage knowledge graphs for dynamic recommendations, for example, by capturing the attention of user's interests that change rapidly over time.
6.4. Learning with Knowledge Graphs
Representation learning has emerged to represent graphs. To create systems that can learn, reason, and generalize from this type of data, relational inductive biases need to be incorporated into deep learning architectures. These advances in graph representation learning have led to new state-of-the-art results in numerous domains such as recommender systems, question answering, and social network analysis [99].
Graph analysis (e.g., random walk) and graph learning (e.g., graph embedding) in recommendation models have achieved great success. Graph-based models have shown potential as the technologies for next-generation recommender systems. Recent efforts in graph representation learning such as KGAT [100], KGCN [101], and KGNN-LS [102] use GNN to synthesize information from such connectivity, strengthening the representation capability and enriching the relationships between a user and an item Wang2020c. These advances show the importance of exploring the potential of neural networks for KG-based recommender systems.
7. Conclusions
This survey presented a comprehensive review of studies related to KG-based recommender systems. Additionally, it identified the technologies used, the level of development, and the contributions of each related work. KG-based recommendation methods have huge potential applications in broad fields: education, healthcare, tourism, e-commerce, entertainment, etc. In this paper, we selected 38 papers, and in at least 8 of them [11,15,16,20,50,51,71,78], the authors found improved performance against baseline or traditional models. On the other hand, according to the work analyzed, there is a lack of complete proposals that include implementing and evaluating the proposals. In fact, 43% of the analyzed proposals have a reference or conceptual description of KG-based recommendation.
Studies on KG for recommender systems demonstrate that KGs are an efficient way to introduce user and item knowledge during the recommendation process. These studies are only the beginning of research in this area, and more research is needed on this topic. Future directions include interpretability and explainability, and the application of improved or hybrid methods by combining machine learning or deep learning techniques to improve the recommendation process. Based on the knowledge and overview obtained in this survey, as future work, the authors plan to design a KG-based recommender system for e-learning.
Finally, the future trends presented in this survey may inspire researchers to conduct further studies in the area of recommendation systems and KG.
Author Contributions
Introduction, J.C. and P.V.-D.; conceptual background, P.V.-D. and J.C.; methodology, J.C.; literature selection, J.C. and P.V.-D.; literature analysis, J.C. and P.V.-D.; research directions, P.V.-D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the Universidad Técnica Particular de Loja and a scholarship provided by the Secretaría Nacional de Educación Superior, Ciencia y Tecnología of Ecuador (SENESCYT).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this review.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CF | Collaborative Filtering |
| KG | Knowledge Graph |
| KGE | Knowledge Graph Embedding |
| LD | Linked Data |
| RS | Recommender System |
References
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. Recommender Systems Handbook; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Zhu, B.; Hurtado, R.; Bobadilla, J.; Ortega, F. An efficient recommender system method based on the numerical relevances and the non-numerical structures of the ratings. IEEE Access 2018, 6, 49935–49954. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.S.; Wang, B.; Zhang, L.; Kong, X. A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Walek, B.; Fojtik, V. A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl. 2020, 158. [Google Scholar] [CrossRef]
- Jia, B.; Huang, X.; Jiao, S. Application of semantic similarity calculation based on knowledge graph for personalized study recommendation service. Kuram Uygulamada Egit. Bilim. 2018, 18, 2958–2966. [Google Scholar] [CrossRef]
- Liu, C.; Li, L.; Yao, X.; Tang, L. A Survey of Recommendation Algorithms Based on Knowledge Graph Embedding. In Proceedings of the 2019 IEEE International Conference on Computer Science and Educational Informatization (CSEI), Kunming, China, 16–19 August 2019; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2019. [Google Scholar]
- Manouselis, N.; Drachsler, H.; Vuorikari, R.; Hummel, H.; Koper, R. Recommender Systems in Technology Enhanced Learning. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Boston, MA, USA, 2011; pp. 387–415. [Google Scholar] [CrossRef]
- Chicaiza, J.; Piedra, N.; Lopez-Vargas, J.; Tovar-Caro, E. Recommendation of Open Educational Resources. An Approach based on Linked Open Data. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017; pp. 1316–1321. [Google Scholar] [CrossRef]
- Deng, Y.; Lu, D.; Huang, D.; Chung, C.J.; Lin, F. Knowledge Graph based Learning Guidance for Cybersecurity Hands-on Labs. In Proceedings of the ACM Conference on Global Computing Education, Chengdu, China, 17–19 May 2019; ACM: New York, NY, USA, 2018; Volume 19. [Google Scholar]
- Li, X.; Chen, Y.; Pettit, B.; De Rijke, M. Personalised reranking of paper recommendations using paper content and user behavior. ACM Trans. Inf. Syst. 2019, 37, 1–23. [Google Scholar] [CrossRef]
- Guo, Q.; Sun, Z.; Zhang, J.; Theng, Y.L. Modeling heterogeneous influences for point-of-interest recommendation in location-based social networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2019; Volume 11496, pp. 72–80. [Google Scholar] [CrossRef]
- Nilashi, M.; bin Ibrahim, O.; Ithnin, N.; Sarmin, N.H. A multi-criteria collaborative filtering recommender system for the tourism domain using Expectation Maximization (EM) and PCA—ANFIS. Electron. Commer. Res. Appl. 2015, 14, 542–562. [Google Scholar] [CrossRef]
- Santhoshi, C.; Thirupathi, V.; Chythanya, K.R.; Aluvala, S.; Sunil, G. A comprehensive study on efficient keyword-aware representative travel route recommendation. Int. J. Adv. Sci. Technol. 2020, 29, 1800–1810. [Google Scholar]
- Wang, H.; Wang, Z.; Hu, S.; Xu, X.; Chen, S.; Tu, Z. DUSKG: A fine-grained knowledge graph for effective personalized service recommendation. Future Gener. Comput. Syst. 2019, 100, 600–617. [Google Scholar] [CrossRef]
- Wu, J.; Zhu, X.; Zhang, C.; Hu, Z. Event-centric tourism knowledge graph—A case study of Hainan. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 12274, pp. 3–15. [Google Scholar] [CrossRef]
- Suzuki, T.; Oyama, S.; Kurihara, M. Explainable Recommendation Using Review Text and a Knowledge Graph. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2019; pp. 4638–4643. [Google Scholar] [CrossRef]
- Gim, J.; Lee, S.; Joo, W. A study of prescriptive analysis framework for human care services based on CKAN cloud. J. Sens. 2018, 2018. [Google Scholar] [CrossRef]
- Wang, F.; Li, Y. An Auto Question Answering System for Tree Hole Rescue. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Science and Business Media Deutschland GmbH: Norwell, MA, USA, 2020; Volume 12435, pp. 15–24. [Google Scholar] [CrossRef]
- Catherine, R.; Mazaitis, K.; Eskenazi, M.; Cohen, W. Explainable Entity-based Recommendations with Knowledge Graphs. In Proceedings of the 11th ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, 27–31 August 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Hu, S.; Tu, Z.; Wang, Z.; Xu, X. A POI-sensitive knowledge graph based service recommendation method. In Proceedings of the 2019 IEEE International Conference on Services Computing (SCC), Milan, Italy, 8–13 July 2019; Part of the 2019 IEEE World Congress on Services. IEEE: Piscataway, NJ, USA, 2019; pp. 197–201. [Google Scholar] [CrossRef]
- Zou, X. A Survey on Application of Knowledge Graph. In Proceedings of the 2020 4th International Conference on Control Engineering and Artificial Intelligence, CCEAI 2020, Singapore, 17–19 January 2020. Journal of Physics: Conference Series. [Google Scholar]
- Nigam, V.; Paul, S.; Agrawal, A.; Bansal, R. A review paper on the application of knowledge graph on various service providing platforms. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science Engineering (Confluence), Noida, India, 29–31 January 2020; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2020; pp. 716–720. [Google Scholar] [CrossRef]
- Lu, F.; Cong, P.; Huang, X. Utilizing Textual Information in Knowledge Graph Embedding: A Survey of Methods and Applications. IEEE Access 2020, 8, 92072–92088. [Google Scholar] [CrossRef]
- Sun, Z.; Guo, Q.; Yang, J.; Fang, H.; Guo, G.; Zhang, J.; Burke, R. Research commentary on recommendations with side information: A survey and research directions. Electron. Commer. Res. Appl. 2019, 37. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Chua, T.S. Learning and reasoning on graph for recommendation. In Proceedings of the WSDM 2020: 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 890–893. [Google Scholar] [CrossRef]
- Rizun, M. Concept of recommender system for building an individual educational profile. In Proceedings of the Conference of 2019 Joint International Conference on Perspectives in Business Informatics Research Workshops and Doctoral Consortium, BIR-WS 2019, Katowice, Poland, 23–25 September 2019; CEUR Workshop Proceedings. CEUR-WS: Aachen, Germany, 2019; Volume 2443, pp. 165–176. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. IEEE Comput. Soc. 2009, 42, 42–49. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z.; Zheng, M.; He, X. Robust non-negative matrix factorization. Front. Electr. Electron. Eng. China 2011, 6, 192–200. [Google Scholar] [CrossRef]
- Zhou, X.; He, J.; Huang, G.; Zhang, Y. SVD-based incremental approaches for recommender systems. J. Comput. Syst. Sci. 2015, 81, 717–733. [Google Scholar] [CrossRef]
- Hernando, A.; Bobadilla, J.; Ortega, F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowl. Based Syst. 2016, 97, 188–202. [Google Scholar] [CrossRef]
- Wen, S.; Wang, C.; Li, H.; Wen, S. Naïve Bayes regression model and its application in collaborative filtering recommendation algorithm. Int. J. Internet Manuf. Serv. 2018, 5, 85–99. [Google Scholar] [CrossRef]
- Valdiviezo-Diaz, P.; Ortega, F.; Cobos, E.; Lara-Cabrera, R. A Collaborative Filtering Approach Based on Naïve Bayes Classifier. IEEE Access 2019, 7, 108581–108592. [Google Scholar] [CrossRef]
- Wasid, M.; Ali, R. An improved recommender system based on multi-criteria clustering approach. Procedia Comput. Sci. 2018, 131, 93–101. [Google Scholar] [CrossRef]
- Bobadilla, J.; Bojorque, R.; Hernando, A.; Hurtado, R. Recommender Systems Clustering using Bayesian non Negative Matrix Factorization. IEEE Access 2018, 3536, 1. [Google Scholar] [CrossRef]
- Ali, M.; Ali, R.; Khan, W.A.; Han, S.C.; Bang, J.; Hur, T.; Kim, D.; Lee, S.; Kang, B.H. A Data-Driven Knowledge Acquisition System: An End-to-End Knowledge Engineering Process for Generating Production Rules. IEEE Access 2018, 6, 15587–15607. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19. [Google Scholar] [CrossRef]
- Sun, F.; Yu, M.; Zhang, X.; Chang, T.W. A vocabulary recommendation system based on knowledge graph for chinese language learning. In Proceedings of the IEEE 20th International Conference on Advanced Learning Technologies, ICALT 2020, Tartu, Estonia, 6–9 July 2020; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2020; pp. 210–212. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Bahramian, Z.; Ali Abbaspour, R.; Claramunt, C. A Cold Start Context-Aware Recommender System for Tour Planning Using Artificial Neural Network and Case Based Reasoning. Mob. Inf. Syst. 2017, 2017, 9364903. [Google Scholar] [CrossRef]
- Drachsler, H.; Hummel, H.; Koper, R. Recommendations for learners are different: Applying memory-based recommender system techniques to lifelong learning. In Proceedings of the 1st Workshop on Social Information Retrieval for Technology-Enhanced Learning & Exchange, Crete, Greece, 18 September 2007. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook; Springer: New York, NY, USA, 2015; Volume 32. [Google Scholar] [CrossRef]
- Blei, D.; Carin, L.; Dunson, D. Probabilistic topic models. IEEE Signal Process. Mag. 2010, 27, 55–65. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Achmad, K.; Nugroho, L.; Djunaedi, A.; Widyawan. Context-aware based restaurant recommender system: A prescriptive analytics. J. Eng. Sci. Technol. 2019, 14, 2847–2864. [Google Scholar]
- Gasmi, I.; Anguel, F.; Seridi-Bouchelaghem, H.; Azizi, N. Context-aware based evolutionary collaborative filtering algorithm. Lect. Notes Netw. Syst. 2021, 156, 217–232. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Colombo-Mendoza, L.O.; Valencia-García, R.; Rodríguez-González, A.; Alor-Hernández, G.; Samper-Zapater, J.J. RecomMetz: A context-aware knowledge-based mobile recommender system for movie showtimes. Expert Syst. Appl. 2015, 42, 1202–1222. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Web Recommender Systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Brusilovsky, P., Kobsa, A., Nejdl, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Luo, J. Knowledge Graph Embedding Based Collaborative Filtering. IEEE Access 2020, 8, 134553–134562. [Google Scholar] [CrossRef]
- Singh, M.; Rishi, O. Event driven recommendation system for E-commerce using knowledge based collaborative filtering technique. Scalable Comput. 2020, 21, 369–378. [Google Scholar] [CrossRef]
- Kiran, R.; Kumar, P.; Bhasker, B. DNNRec: A novel deep learning based hybrid recommender system. Expert Syst. Appl. 2020, 144, 113054. [Google Scholar] [CrossRef]
- Khan, Z.; Niu, Z.; Nyamawe, A.; Haq, I. A Deep Hybrid Model for Recommendation by jointly leveraging ratings, reviews and metadata information. Eng. Appl. Artif. Intell. 2021, 97. [Google Scholar] [CrossRef]
- Peska, L. Hybrid recommendations by content-aligned Bayesian personalized ranking. New Rev. Hypermedia Multimed. 2018, 24, 88–109. [Google Scholar] [CrossRef]
- Ngaffo, A.; Ayeb, W.; Choukair, Z. A Bayesian Inference Based Hybrid Recommender System. IEEE Access 2020, 8, 101682–101701. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and analysis of a cluster-based intelligent hybrid recommendation system for e-learning applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Sandeep Kumar, M.; Prabhu, J. A hybrid model collaborative movie recommendation system using K-means clustering with ant colony optimisation. Int. J. Internet Technol. Secur. Trans. 2020, 10, 337–354. [Google Scholar] [CrossRef]
- Wang, Q.; Long, M.; Yang, H. A Non-Negative Matrix-Factorization-Based Network Embedding Approach for Hybrid Recommender Systems. In Proceedings of the 2020 International Conference on Computing, Networks and Internet of Things, Sanya, China, 24–26 April 2020; CNIOT2020. Association for Computing Machinery: New York, NY, USA, 2020; pp. 105–110. [Google Scholar] [CrossRef]
- Zhou, J.; Wen, J.; Li, S.; Zhou, W. From Content Text Encoding Perspective: A Hybrid Deep Matrix Factorization Approach for Recommender System. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Achary, N.; Patra, B. Graph Based Hybrid Approach for Long-Tail Item Recommendation in Collaborative Filtering. In ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2020; p. 426. [Google Scholar] [CrossRef]
- Li, J.; Xu, Z.; Tang, Y.; Zhao, B.; Tian, H. Deep hybrid knowledge graph embedding for top-n recommendation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2020; Volume 12432, pp. 59–70. [Google Scholar] [CrossRef]
- Musto, C.; Basile, P.; Semeraro, G. Hybrid Semantics-Aware Recommendations Exploiting Knowledge Graph Embeddings. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2019; Volume 11946, pp. 87–100. [Google Scholar] [CrossRef]
- Kazemi, S.; Goel, R.; Jain, K.; Kobyzev, I.; Sethi, A.; Forsyth, P.; Poupart, P. Representation learning for dynamic graphs: A survey. J. Mach. Learn. Res. 2020, 21, 1–73. [Google Scholar]
- Ameen, A. Knowledge based Recommendation System in Semantic Web—A Survey. Int. J. Comput. Appl. 2019, 182, 20–25. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Chari, S.; Qi, M.; Agu, N.N.; Seneviratne, O.; McCusker, J.P.; Bennett, K.P.; Das, A.K.; McGuinness, D.L. Making Study Populations Visible Through Knowledge Graphs. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2019; Volume 11779, pp. 53–68. [Google Scholar] [CrossRef]
- Ali, L.; Mathew, S. Knowledge Base Construction from Unstructured Text. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 569–574. [Google Scholar]
- Bi, Y.; Song, L.; Yao, M.; Wu, Z.; Wang, J.; Xiao, J. DCDIR: A Deep Cross-Domain Recommendation System for Cold Start Users in Insurance Domain. In Proceedings of the SIGIR 2020: 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi'an, China, 25–30 July 2020; ACM, Inc.: New York, NY, USA, 2020; pp. 1661–1664. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Dong, X.; Li, T.; Ding, Z. An ontology enhanced user profiling algorithm based on application feedback. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; IEEE Computer Society: Washington, DC, USA, 2019; Volume 1, pp. 316–325. [Google Scholar] [CrossRef]
- Esteban, C.; Yang, Y.; Tresp, V. Embedding mapping approaches for tensor factorization and knowledge graph modelling. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016; Volume 9678, pp. 199–213. [Google Scholar] [CrossRef]
- Fischer, L.; Blanco, R.; Mika, P.; Bernstein, A. Timely semantics: A study of a stream-based ranking system for entity relationships. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9367, pp. 429–445. [Google Scholar] [CrossRef]
- Li, A.; Wang, X.; Wang, W.; Zhang, A.; Li, B. A survey of relation extraction of knowledge graphs. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2019; Volume 11809, pp. 52–66. [Google Scholar] [CrossRef]
- Oramas, S.; Ostuni, V.C.; Di Noia, T.; Serra, X.; Di Sciascio, E. Sound and music recommendation with knowledge graphs. ACM Trans. Intell. Syst. Technol. 2016, 8, 1–21. [Google Scholar] [CrossRef]
- Chari, S. Ontology-Enabled Analysis of Study Populations; ISWC Satellites 2019; CEUR: Luxembourg, 2019. [Google Scholar]
- Tomeo, P.; Fernández-Tobías, I.; Cantador, I.; Di Noia, T. Addressing the Cold Start with Positive-Only Feedback Through Semantic-Based Recommendations. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2017, 25, 57–78. [Google Scholar] [CrossRef]
- Tumpa, S.N.; Masroor Ali, M. Document Concept Hierarchy Generation by Extracting Semantic Tree Using Knowledge Graph. In Proceedings of the 2018 IEEE International WIE Conference on Electrical and Computer Engineering, WIECON-ECE 2018, Chonburi, Thailand, 14–16 December 2018; IEEE Inc.: Piscataway, NJ, USA, 2018; pp. 83–86. [Google Scholar] [CrossRef]
- Wang, Q.; Xiong, Y.; Zhu, Y.; Yu, P.S. KASR: Knowledge-Aware Sequential Recommendation. In Web and Big Data; Wang, X., Zhang, R., Lee, Y.K., Sun, L., Moon, Y.S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 493–508. [Google Scholar]
- Wu, J.; Lécué, F.; Gueret, C.; Hayes, J.; van de Moosdijk, S.; Gallagher, G.; McCanney, P.; Eichelberger, E. Personalizing actions in context for risk management using semantic web technologies. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2017; Volume 10588, pp. 367–383. [Google Scholar] [CrossRef]
- Zhao, X.; Zeng, W.; Tang, J.; Wang, W.; Suchanek, F. An Experimental Study of State-of-the-Art Entity Alignment Approaches. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Zhu, S.; Li, Y.; Shao, Y.; Wang, L. Building Semantic Dependency Knowledge Graph Based on HowNet. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 11831, pp. 525–534. [Google Scholar] [CrossRef]
- Qin, C.; Zhu, H.; Zhuang, F.; Guo, Q.; Zhang, Q.; Zhang, L.; Wang, C.; Chen, E.; Xiong, H. A survey on knowledge graph-based recommender systems. Sci. Sin. Inf. 2020, 50, 937–956. [Google Scholar] [CrossRef]
- Forouzandeh, S.; Berahmand, K.; Rostami, M. Presentation of a recommender system with ensemble learning and graph embedding: A case on MovieLens. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Zhou, K.; Zhao, W.X.; Bian, S.; Zhou, Y.; Wen, J.R.; Yu, J. Improving Conversational Recommender Systems via Knowledge Graph Based Semantic Fusion. In KDD '20: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery I& Data Mining; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1006–1014. [Google Scholar] [CrossRef]
- Sarkar, R.; Goswami, K.; Arcan, M.; McCrae, J.P. Suggest me a movie for tonight: Leveraging Knowledge Graphs for Conversational Recommendation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December; International Committee on Computational Linguistics: Barcelona, Spain (Online), 2020; pp. 4179–4189. [Google Scholar] [CrossRef]
- Carrer-Neto, W.; Hernández-Alcaraz, M.L.; Valencia-García, R.; García-Sánchez, F. Social knowledge-based recommender system. Application to the movies domain. Expert Syst. Appl. 2012, 39, 10990–11000. [Google Scholar] [CrossRef]
- Teng, Y.; Shi, Y.; Tsai, J.; Shuai, H.; Tai, C.; Yang, D. Optimizing Social-Topic Engagement on Social Network and Knowledge Graph. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, M.; Liu, P. Performance Evaluation of Recommender Systems. Int. J. Perform. Eng. 2017, 13, 1246–1256. [Google Scholar] [CrossRef]
- Mendoza, M.; Torres, N. Evaluating content novelty in recommender systems. J. Intell. Inf. Syst. 2020, 54, 297–316. [Google Scholar] [CrossRef]
- Kunaver, M.; PoÅŸrl, T. Diversity in recommender systems: A survey. Knowl. Based Syst. 2017, 123, 154–162. [Google Scholar] [CrossRef]
- Díez, J.; Martínez-Rego, D.; Alonso-Betanzos, A.; Luaces, O.; Bahamonde, A. Optimizing novelty and diversity in recommendations. Prog. Artif. Intell. 2019, 8, 101–109. [Google Scholar] [CrossRef]
- Zhong, Y.; Song, X.; Yang, B.; Jiang, C.; Luo, X. An Interpretable Recommendations Approach Based on User Preferences and Knowledge Graph. In Advances in Swarm Intelligence; Tan, Y., Shi, Y., Niu, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 326–337. [Google Scholar]
- Palumbo, E.; Monti, D.; Rizzo, G.; Troncy, R.; Baralis, E. entity2rec: Property-specific knowledge graph embeddings for item recommendation. Expert Syst. Appl. 2020, 151, 113235. [Google Scholar] [CrossRef]
- Lully, V.; Laublet, P.; Stankovic, M.; Radulovic, F. Enhancing explanations in recommender systems with knowledge graphs. Procedia Comput. Sci. 2018, 137, 211–222. [Google Scholar] [CrossRef]
- Xie, L.; Hu, Z.; Cai, X.; Zhang, W.; Chen, J. Explainable recommendation based on knowledge graph and multi-objective optimization. Complex Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Nasiri, M.; Minaei, B.; Kiani, A. Dynamic Recommendation: Disease Prediction and Prevention Using Recommender System. Int. J. Basic Sci. Med. 2016, 1, 13–17. [Google Scholar] [CrossRef]
- Tareq, S.U.; Noor, M.H.; Bepery, C. Framework of dynamic recommendation system for e-shopping. Int. J. Inf. Technol. 2020, 12, 135–140. [Google Scholar] [CrossRef]
- Ma, J.; Chen, H.; Jiang, S.; Huang, Z. A dynamic recommendation approach in online social networks. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 364–369. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph Representation Learning Hamilton; Morgan and Claypool Publishers: San Rafael, CA, USA, 2020; Volume 14, pp. 1–159. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 950–958. [Google Scholar] [CrossRef]
- Kojima, R.; Ishida, S.; Ohta, M.; Iwata, H.; Honma, T.; Okuno, Y. kGCN: A graph-based deep learning framework for chemical structures. J. Cheminform. 2020, 12, 32. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-Aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 968–977. [Google Scholar] [CrossRef]
Figure 1. Methodology: stages and tasks carried on to search, select, and analyze the related literature.
Figure 1. Methodology: stages and tasks carried on to search, select, and analyze the related literature.
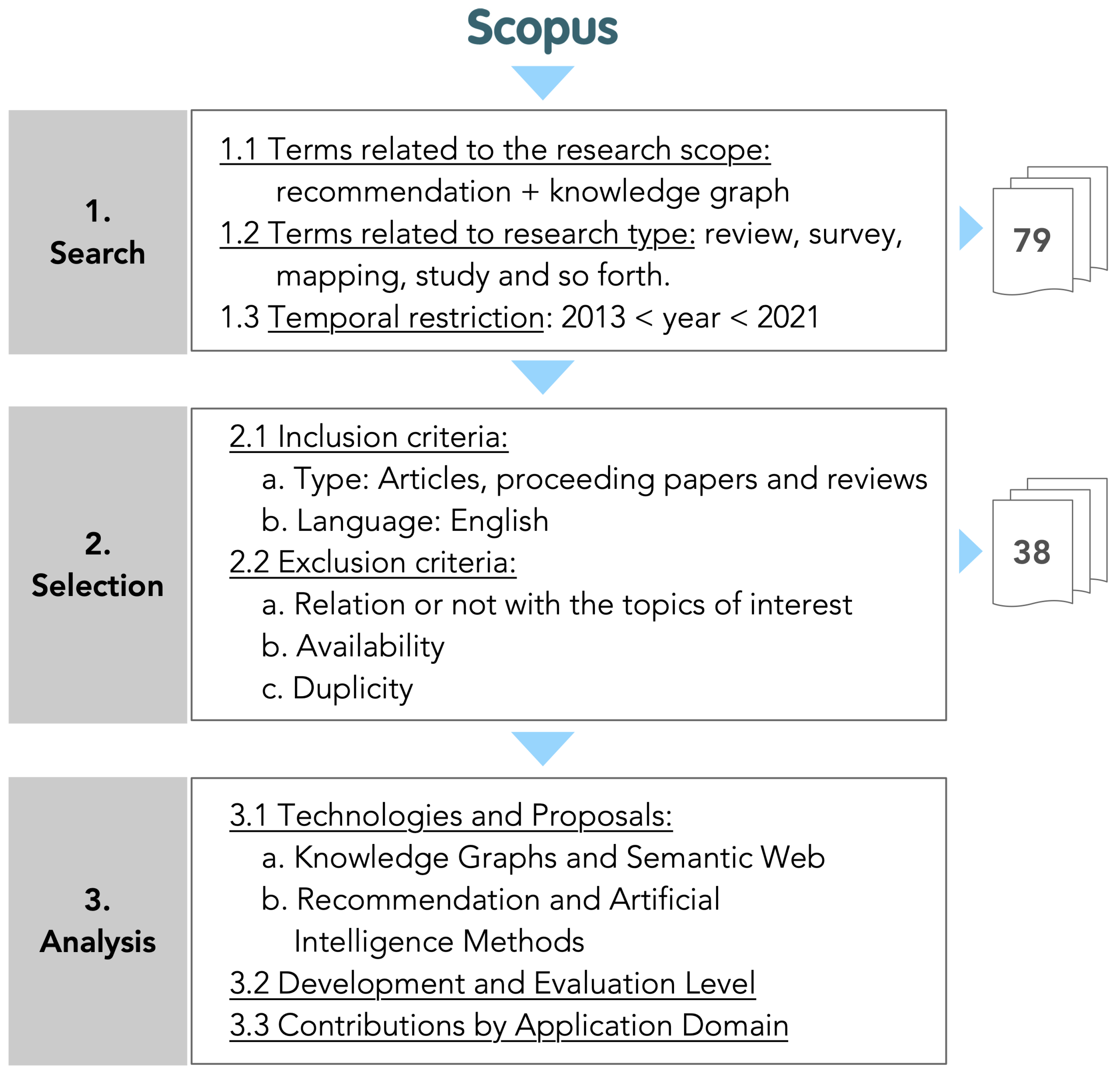
Figure 2. Annual production of papers indexed by Scopus. The stacked area plot shows the temporal evolution of papers related to the topic recommendation systems and knowledge graph.
Figure 2. Annual production of papers indexed by Scopus. The stacked area plot shows the temporal evolution of papers related to the topic recommendation systems and knowledge graph.

Figure 3. Network of more relevant keywords related to the selected papers.
Figure 3. Network of more relevant keywords related to the selected papers.
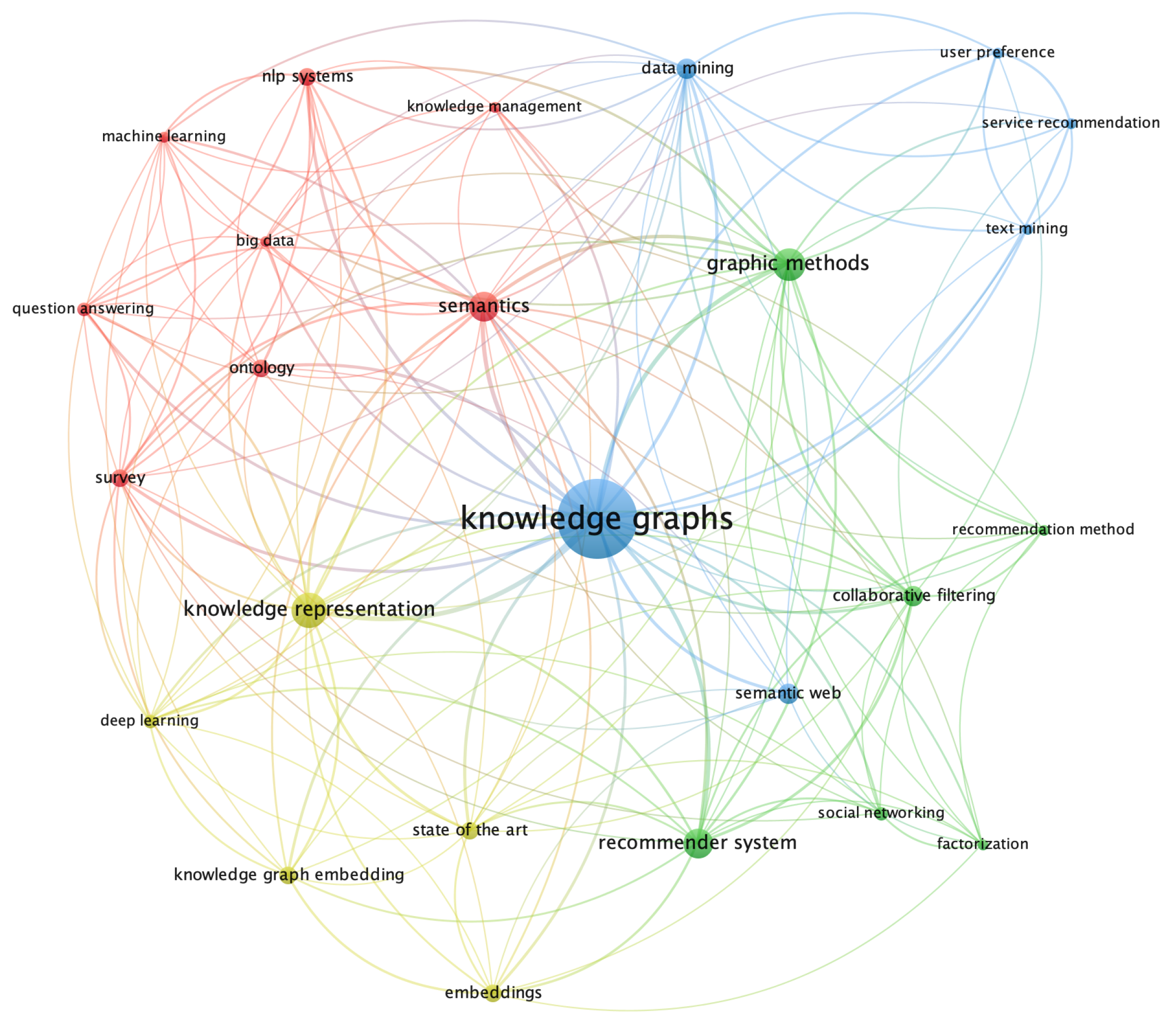
Figure 4. Terms network built from titles and abstracts of the selected papers.
Figure 4. Terms network built from titles and abstracts of the selected papers.
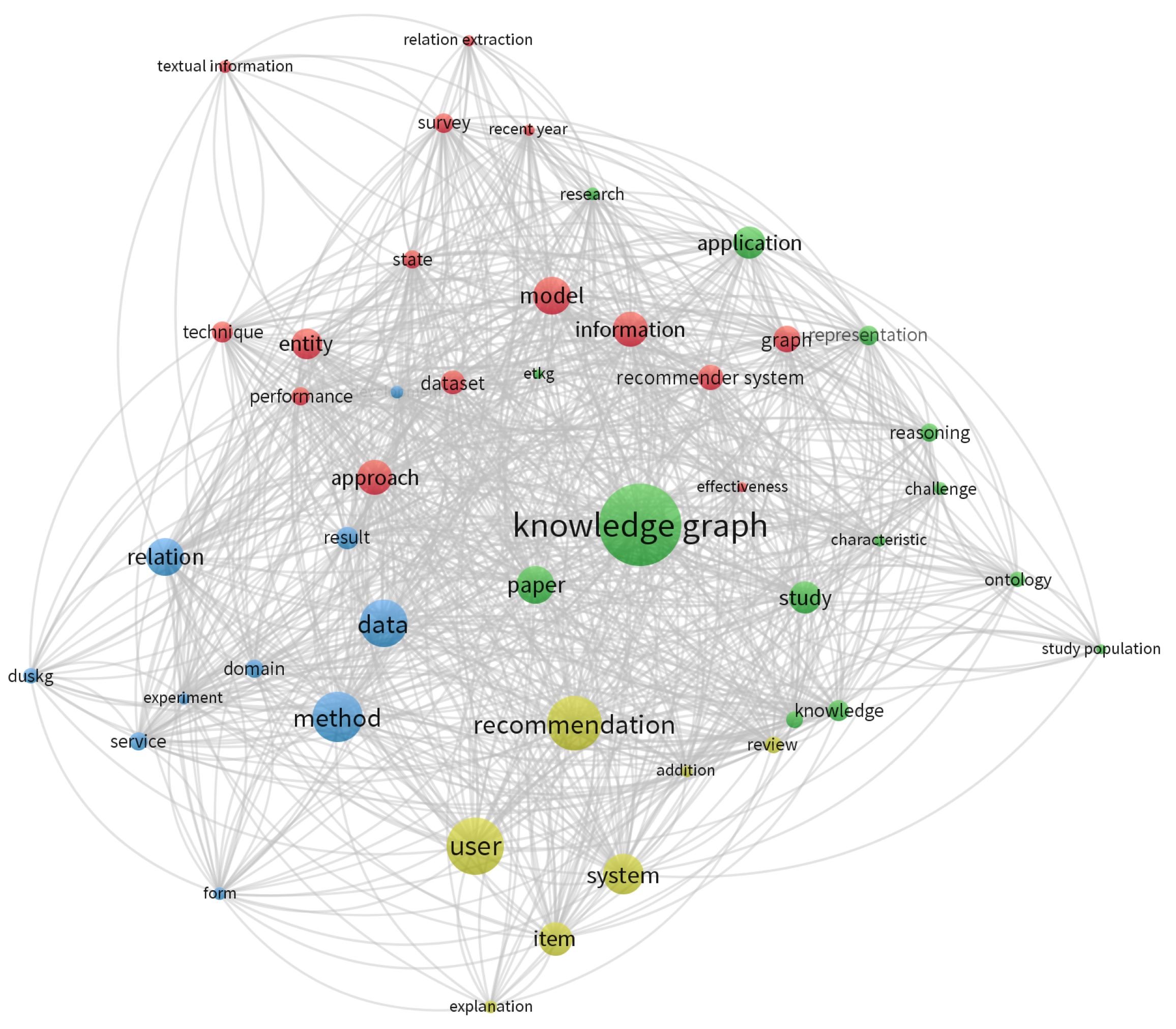
Figure 5. Development and evaluation type.
Figure 5. Development and evaluation type.

Table 1. Knowledge graphs and semantic technologies.
Table 1. Knowledge graphs and semantic technologies.
| Reference | KG and LD | KGE | Ontology | Query Language | Reasoning & Inference | Data Technology |
|---|---|---|---|---|---|---|
| [5] | X | |||||
| [6] | X | |||||
| [9] | X | |||||
| [10] | X | |||||
| [11] | X | |||||
| [13] | X | X | ||||
| [14] | X | |||||
| [15] | X | X | X | X | ||
| [16] | X | |||||
| [17] | X | X | X | |||
| [18] | X | |||||
| [19] | X | |||||
| [20] | X | X | X | |||
| [21] | X | |||||
| [22] | X | |||||
| [23] | X | |||||
| [24] | X | |||||
| [25] | X | |||||
| [50] | X | X | ||||
| [51] | X | |||||
| [63] | X | X | X | |||
| [65] | X | |||||
| [66] | X | X | X | |||
| [67] | X | X | ||||
| [68] | X | |||||
| [69] | X | X | ||||
| [70] | X | X | X | |||
| [71] | X | |||||
| [72] | X | |||||
| [73] | X | |||||
| [74] | X | X | ||||
| [75] | X | X | ||||
| [76] | X | X | ||||
| [77] | X | X | ||||
| [78] | X | X | ||||
| [79] | X | X | X | X | ||
| [80] | X | X | ||||
| [81] | X | X | X | |||
| Total | 23 | 21 | 10 | 3 | 3 | 6 |
Table 2. Recommendation approaches used in the analyzed papers.
Table 2. Recommendation approaches used in the analyzed papers.
| Reference | Collaborative Filtering | Content Filtering | Context-Aware | Knowledge-Based |
|---|---|---|---|---|
| [5] | X | X | X | |
| [6] | ||||
| [9] | X | |||
| [10] | X | X | ||
| [11] | X | X | ||
| [13] | X | |||
| [14] | X | X | ||
| [15] | X | X | ||
| [16] | X | X | ||
| [17] | X | |||
| [18] | X | |||
| [19] | X | X | ||
| [20] | X | X | ||
| [21] | ||||
| [22] | ||||
| [23] | ||||
| [24] | X | x | ||
| [25] | X | |||
| [50] | X | X | ||
| [51] | X | |||
| [63] | ||||
| [65] | ||||
| [66] | X | |||
| [67] | ||||
| [68] | X | X | ||
| [69] | ||||
| [70] | X | X | ||
| [71] | X | |||
| [72] | X | X | ||
| [73] | ||||
| [74] | X | X | ||
| [75] | ||||
| [76] | X | X | ||
| [77] | X | |||
| [78] | X | |||
| [79] | X | |||
| [80] | ||||
| [81] | X |
Table 3. Data sources used by literature.
Table 3. Data sources used by literature.
| Domain | Recommended Item | Datasource | References |
|---|---|---|---|
| Education | Labs | Course data | [9] |
| Learning concepts | Educational resources | [5] | |
| Papers | ScienceDirect | [10] | |
| Health | Questions | Online Suicide Rescue Instruction | [18] |
| Treatments | Not specified | [66,75] | |
| User's behavior | CKAN | [17] | |
| Lodging and Tourism | POIs | Hainan tourism | [15] |
| Social networks | [11] | ||
| POIs, restaurant services & travel routes | Yelp dataset | [11,13,14] | |
| Hotels | Tripadvisor | [16] | |
| Entertainment | Sound and music | Freesound.org | [74] |
| Last.fm | [50,74,78] | ||
| Songfacts.com | [74] | ||
| Facebook music | [76] | ||
| Images | [50] | ||
| Movies | Facebook movies | [76] | |
| IMDB | [19] | ||
| Movielens | [50,71,78] | ||
| Not specified | [24] | ||
| Books | Facebook books | [76] | |
| Not specified | Not specified | [69] | |
| E-Commerce, business and Financial | Business services | Yelp dataset | [20] |
| Insurance products | JGJISNF dataset | [68] | |
| Products | Retail e-Shop | [51] | |
| Toys | Amazon toys | [50] | |
| Books | Amazon books | [78] | |
| Music | Amazon music | [50] | |
| Financial actions | No specified | [79] | |
| Software apps | Apple App store | [70] | |
| Cross-domain | Entities/relationships | Search logs | [72] |
| DBP15K, DWY100K, SRPRS | [80] | ||
| Wikipedia, Bengali documents | [77] | ||
| Food industry | Amino Acid Dataset Freebase | [71] | |
| Language units | HowNet, Wikipedia & a newspaper | [81] | |
| Web resources | Not specified | [22] | |
| Not specified | Not specified | [6,21,25,63,65,67] |
| Publisher's Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Building Event-centric Knowledge Graphs From News
Source: https://www.mdpi.com/2078-2489/12/6/232/htm